

Multiple mental models of the mind
A meandering exploration of what we mean by intelligence


How should we mentally model the human mind? And should we use the same sort of model to understand Artificial Intelligence systems?
These two questions are the undercurrent to nearly everything we talk about around these parts, given that Cognitive Resonance is premised on the idea that exploring them in tandem can build useful (human) knowledge. So I’ve made my bet—sprinkled just about everywhere here you’ll find the “simple model of the mind” made famous by my friend and collaborator Dan Willingham, with my “simple model of AI” lurking nearby. The new Cognitive Resonance website now even has animated versions of both, and oh hey, why not take a quick peek at the snazzy new site, hmm? (Ah, subtle.)
The chief virtue of the simple model of the mind is also its Achilles’ heel—it’s, um, very simple. At least on its face. I like to quip in my workshops that the model takes five minutes to learn, and a lifetime to understand its implications. But for people unfamiliar with cognitive science, it provides a helpful and accessible entry point into how scientists within this discipline conceive of how our minds work, and the basic cognitive architecture of how we process new information and—potentially—convert this to durable knowledge in our heads.
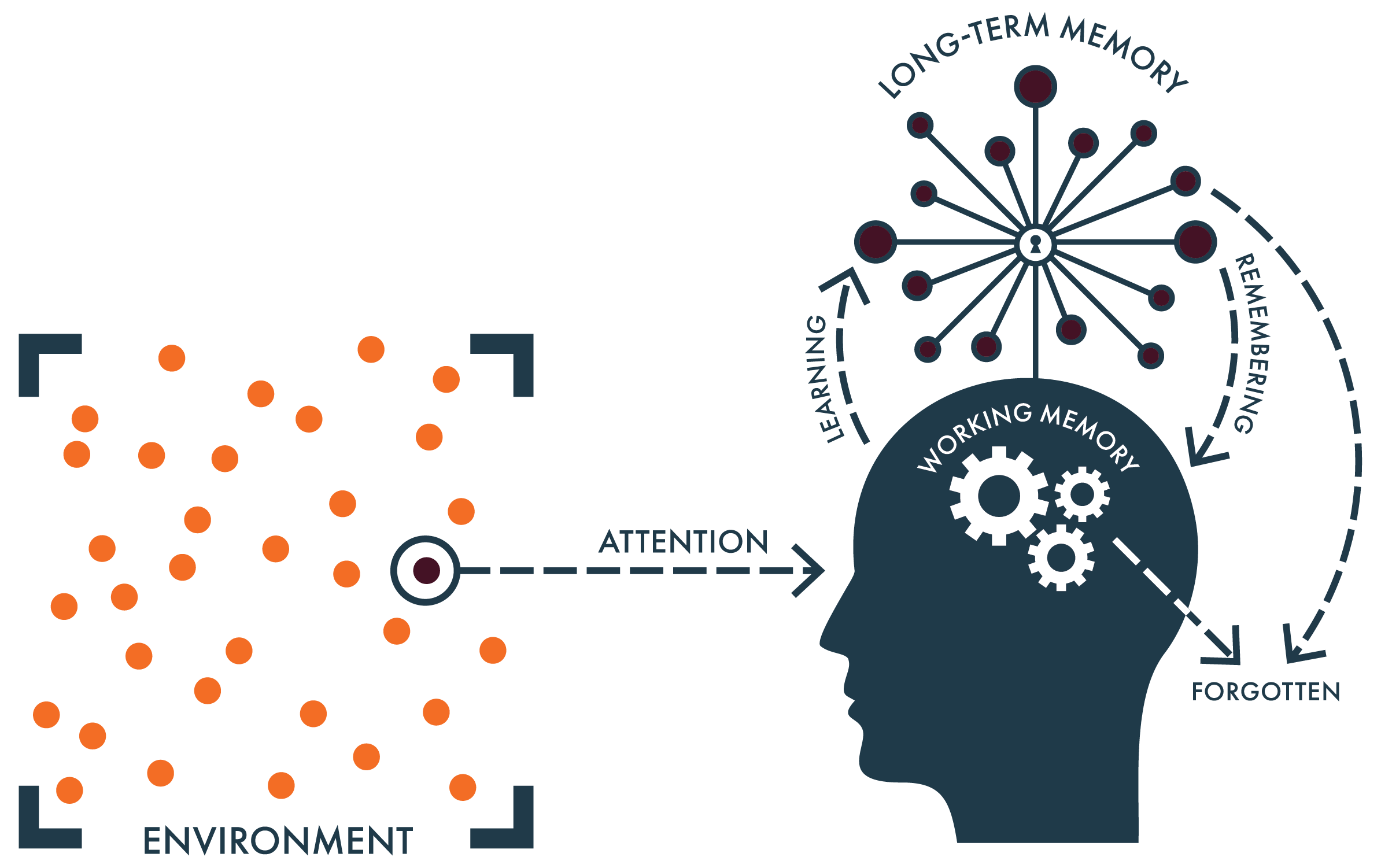
We can of course complicate this model. One thing you might notice is that nowhere does the word “intelligence” appear in it, an interesting omission that has its pros and cons in the work that I do. Pro: People are nervous whenever the word “intelligence” is invoked, for many understandable reasons, a few of which we’ll get to shortly. Con: By tip-toeing around intelligence as a concept, we may be inadvertently hobbling our mental model of our minds, and in particular, how we learn.
Recently, my friend Dylan Kane, a teacher in Colorado (and Cognitive Resonance collaborator), wrote an interesting essay on this subject, provocatively titled “Why Some Students Learn Faster.” I’m a close reader of everything Dylan writes, and for some time he’s gently been pushing for educators to become less fearful of talking about the intelligence of students, and what we mean when we talk about being “smart.” In so doing, he offers up a mental model of intelligence that intersects/overlaps/augments the simple model of the mind:
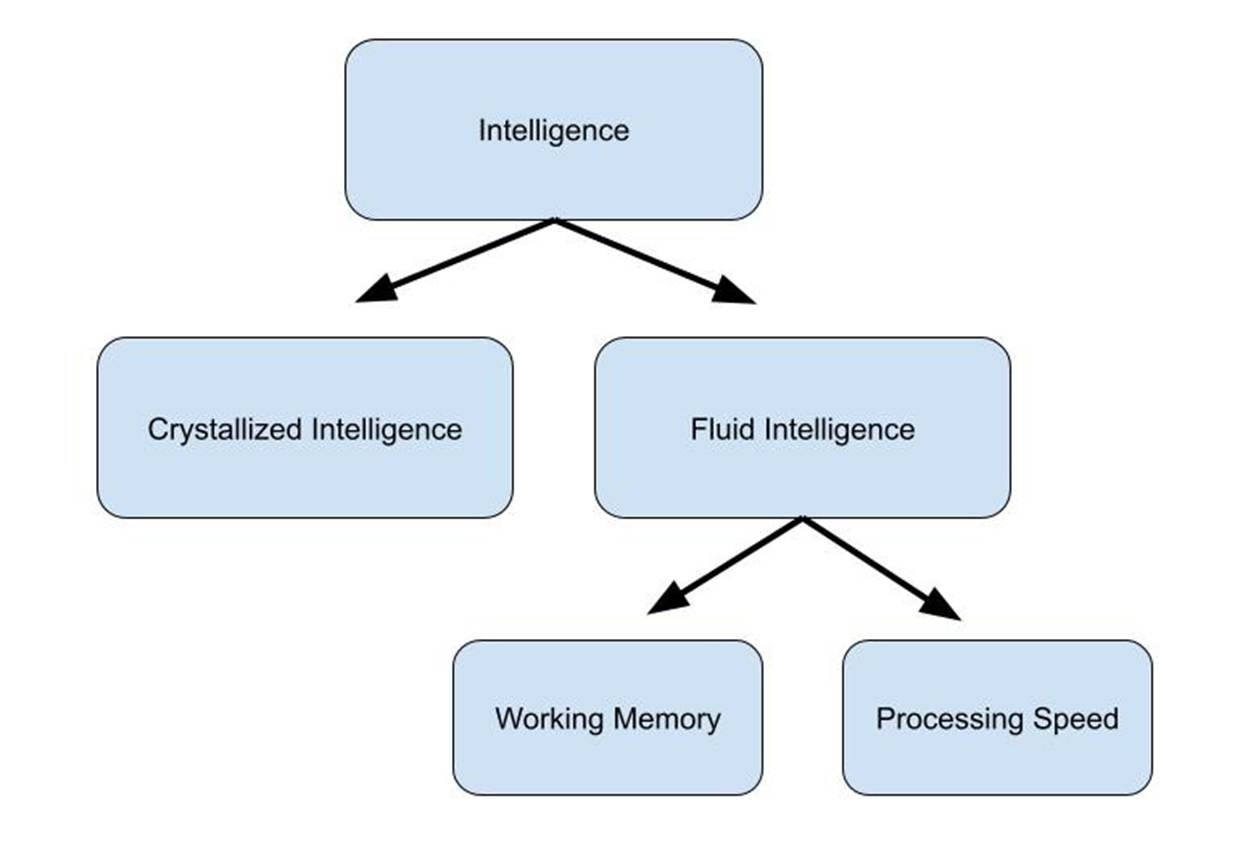
Based on his review of the research, Kane contends that when teachers observe that some students learn faster than others, much of this may be driven by the variance in kids’ working memory capacities and speeds of information processing—that’s the fluid intelligence box. The third rail that I will now touch very gingerly: Scientifically speaking, it’s likely that some of this variance is influenced by genetic factors (but please bear with me, as I’ll explain shortly why this does not mean what at least one prominent education commentator suggests). Regardless of the cause of differences in fluid intelligence, however, Kane’s point is that understanding that such differences exist provides helpful guidance to teachers as to what to do in the classroom, among them constant checking of background knowledge, breaking down concepts into small steps, and frequent practice to build confidence in learners. Hear, hear.
There are however dangers that arise whenever we complicate our mental model of human cognition, across at least two dimensions. First, there’s the risk that we’ll lose a basic value of the model in simplifying complexity to improve our understanding of the whatever’s being modeled. Second, there’s the risk that this complexity will lead to misrepresentations of the modeled phenonmena in ways that prove unhelpful. It’s this latter issue I see frequently crop up in education, so let’s take a brief detour to examine two examples.
We’ll start with Freddie deBoer and his book Cult of Smart. His basic argument, which he’s advanced for several years, is that intelligence is predominately driven by genetic forces, and that we should not expect schooling or any other environmental factor to surmount this (alleged) hard scientific truth. The driver of our intelligence is our “natural talents, the inborn academic tendencies that shape our successes and failures at school.”
As I’ve written previously, I think deBoer is simply wrong about all this, scientifically speaking. Briefly, among the mistakes I see him making are (a) believing that genetic “heritability” equates to “the amount we can say that a particular human trait, such as intelligence, is genetically caused,” which is wrong; (b) deliberately downplaying one of the major insights arising over the last several decades of research in behavioral genetics, which underscores just how entangled genetic and environmental influences really are; and (c) assuming that there exists some essential thing within our brains called “intelligence,” rather than seeing it as a statistical artifice. As Eric Turkheimer recently wrote, “we do not understand the genetic or brain mechanisms that cause some people to be more intelligent than others.” We should continue to resist the claim that our cognitive capabilities are fixed by the genome.1
The second example of misguided public commentary on intelligence comes from the opposite direction via Howard Gardner, a psychologist who’s online bio currently designates him as “Research Professor of Cognition and Education at the Harvard Graduate School of Education.” More than 40 years ago, Gardner became prominent for his theory of “multiple intelligences,” which posits that we humans do not possess some single unitary general cognitive capacity called intelligence but rather, well, a bunch of independent, stand-alone types of intelligences that vary considerably. Among these, Gardner contends, include “linguistic” intelligence (being good at talking and writing), “body-kinesthetic” intelligence (being good at dancing), and “naturalist” intelligence (being good at picking flowers, and I’m only slightly exaggerating).
Purely from a rhetorical perspective, multiple-intelligences theory appeals to me, in part because it opens up an avenue to talk about intelligence in a way that is less threatening to identity, and more accommodating to the diversity of human talents we observe around us (and in our kids). Indeed, I suspect it’s for precisely this reason that Gardner’s theory quickly caught on in schools of education in the US, and education systems more broadly. I get it, I do. We want to believe, I want to believe, that every human is intelligent in their own special way.
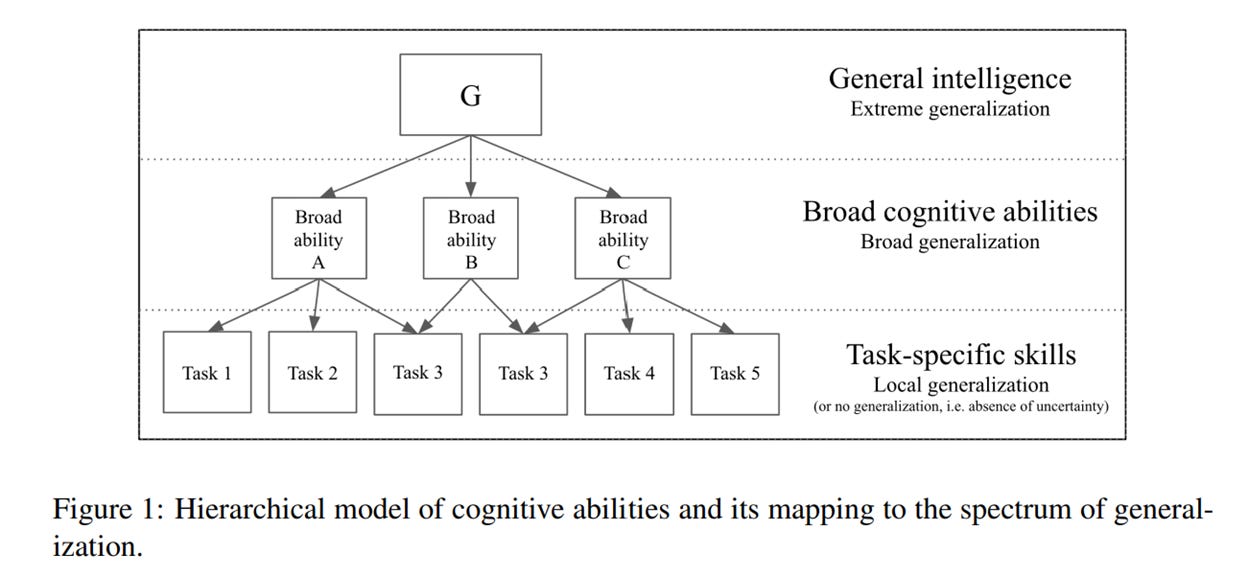
From a scientific perspective, however, the problem is that multiple-intelligences theory isn’t true (or remains unsupported empirically, if you prefer softer language). In a review of Gardner’s efforts written nearly 20 years ago, Dan Willingham—yes, him again!—pointed out a number of flaws that were as true then as they are today. For one, cognitive science has already moved on from conceptualizing intelligence as a purely unitary capacity, to one instead that models intelligence as a hierarchy (we’ll come back to this in the AI section below, and yes we’re getting there). For another, because there’s no empirical program that’s developed around identifying multiple intelligences, there’s no limiting factor to defining what they include, leading Willingham to wryly observe that we could just as easily add “humor intelligence” and “olfactory intelligence” and whatever else to the list.
So multiple intelligences: Not a thing. For that reason, I hope that when people see Gardner speaking on panels nowadays about AI and what it portends for education, and hear him contend that “cognitive aspects of mind…will be done so well by large language machines and mechanisms that whether we do them as humans will be optional,” well, I hope we significantly discount this prediction. Gardner doesn’t have a crystal ball, and the claims he advanced midway through his career never cashed out. Why should we think he’ll be right this time around?
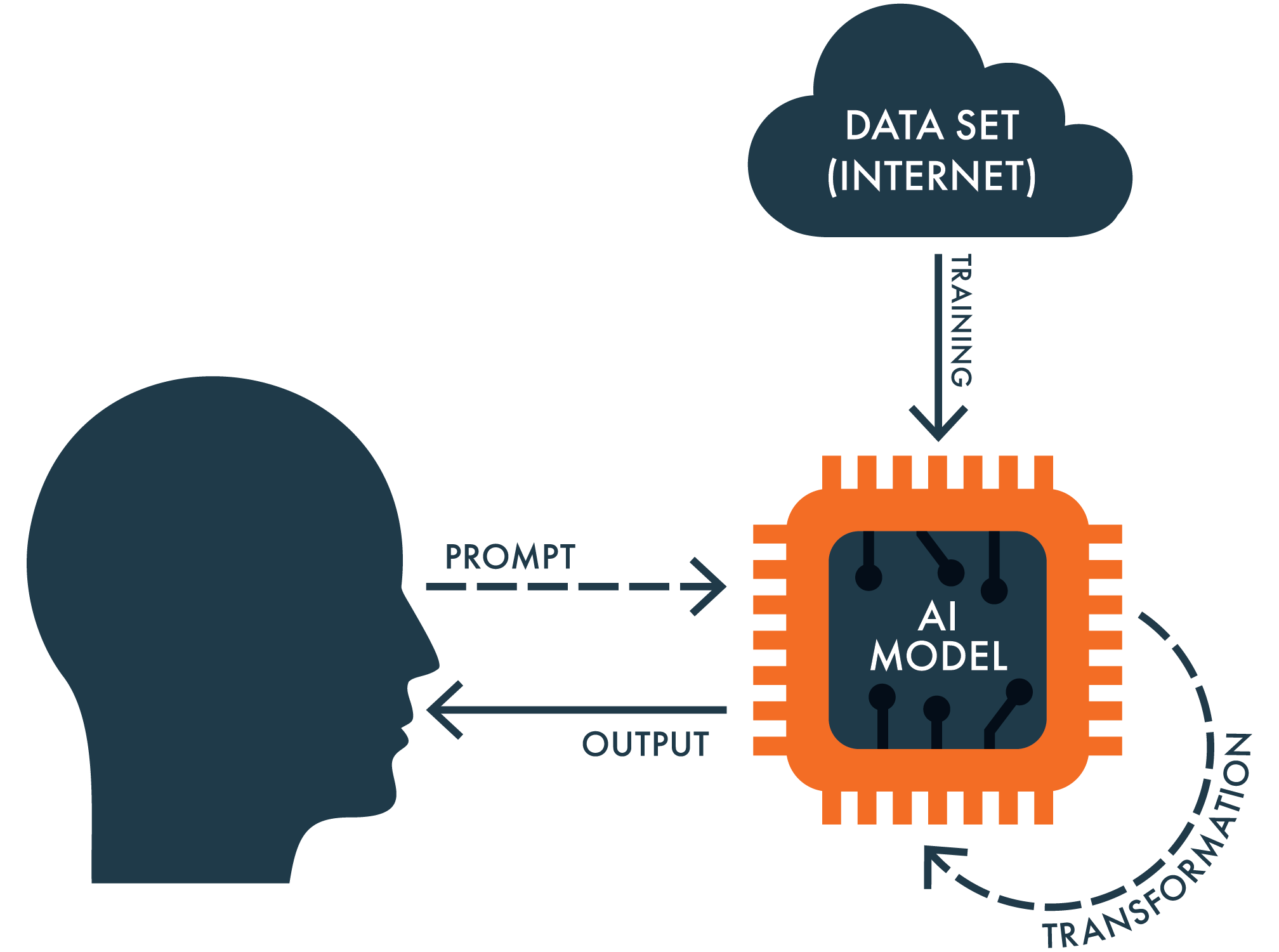
At long last, we can turn to AI, and how we should build our mental model of it. More specifically, I want to ask—but not entirely answer—the question of whether the dominant model of human intelligence is a useful one in guiding the project of developing “artificial general intelligence,” something as smart or smarter than ourselves.
Six years ago, François Chollet, then with Google DeepMind (and now co-founder of Ndea, a new intelligence science lab), wrote an influential paper, “On the Measure of Intelligence,” with an unambiguous answer to this question: Yes. I mentioned earlier that the dominant model of intelligence within the field of cognitive science is hierarchical, which is the same model that informs Chollet’s approach to evaluating human and artificial intelligence:
Back when this newsletter had like 30 followers, I wrote about Chollet’s thesis and the test he’s created, called ARC-AGI, that aims at evaluating both human and AI capacity to solve novel tasks that involve abstract reasoning. Without going into all of the details, the problem sets look like this:
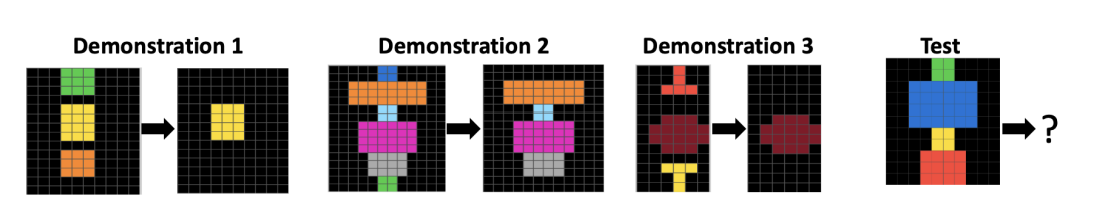
Can you spot the pattern? Feels very IQ-test like, right? And that’s by design. Chollet’s premise is that we should have some measurable way to define the capacity for “extreme generalization,” the ability to handle complex novel tasks without specific prior training, and that we should use the same test of humans and AI systems to see if the latter have progressed to become as intelligent, or more intelligent, than we are.
By that measure, well, AGI has all but arrived! Over the last year, so-called “reasoning” versions of large-language models have dramatically improved on the ARC-AGI test, and some have even surpassed human-level performance. But here’s whether things get even more complicated. For some time, Melanie Mitchell at the Santa Fe Institute has maintained that AI model performance on ARC-AGOI might be misleading if the models are solving the tasks differently than we humans are. Recently, she and her SFI colleagues released a pre-print paper wherein they found that AI models often use “surface-level shortcuts” on these tasks, and thus “capture intended abstractions substantially less often than do humans.” As a result, the capabilities of AI models “for general abstract reasoning may be overestimated by evaluations based on accuracy alone.” In other words, to achieve anything akin to artificial general intelligence that mirrors our own, how these models solve the problems matters, lest they project the illusion of intelligence.
I know, it’s dizzying. And right now anyone of the “connectionist” school of cognition is chomping at the bit to rebut these claims. Their argument, I will quickly paraphrase, would be something along the lines of, “yes well all this was said prior to the advent of large-language models using the transformation architecture and attention mechanism, yet these models have proven far more capable than what this classical approach predicted, so just give us more money for data centers and Nvidia chips and let’s just see what happens mmmkay?”. They have a point! I don’t agree with them, of course, but billions of dollars are flowing in to test their hypothesis. We shall see.
All of which brings me to the final (I promise) mental model I want to share with you. A few weeks ago, a slew of researchers from across the AI community came together to offer yet another possible definition of artificial general intelligence, namely: “an AI that can match or exceed the cognitive versatility and proficiency of a well-educated adult.” Instead of trying to move up the hierarchical model to find the elusive capacity of extreme generalization, the signatories to this effort propose instead a sort of bottom-up perspective, one where we view AGI as simply the aggregate composition of a bunch of various cognitive skills, leading to this intriguing visual:
Once we get those red lines to expand to the outer rim of this spider web, the claim goes, we will have achieved AGI. And they even built a cool interactive tool to explore each subcomponent here in more detail. Check it out.
My friend Gary Marcus, who signed on to this effort, describes this as an “opening bid” to create some sort of coherency to the AGI discussion, while noting—rightly, I’d say—that this approach is fraught with complicated questions. Can we, should we, aggregate individual cognitive capabilities and deem the resulting sum to be general intelligence? How do we define what weights they should be given, and what capabilities to include? What exactly do we mean by knowledge in this context? It feels reminiscent of the same issues that plague Gardner’s multiple-intelligences theory, with no obvious limiting factor to what gets included in or excluded from the AGI model.
I’ll leave you with this. Back in June 2023, in the early days of our new ChatGPT reality, science historian Jessica Riskin wrote about AI and intelligence and Alan Turing and his infamous test, and referenced in part a BBC panel Turing appeared on with his mentor Max Newman. During that conversation, Turing struggled to describe his own reflections on his thinking—“a sort of buzzing that went on inside my head”—and, fascinatingly, suggested that intelligence conceptually dissolves the more we use the tools of science to explain it. Riskin reports what happened next:
Newman agreed, drawing an analogy to the beautiful ancient mosaics of Ravenna. If you scrutinized these closely, you might say, “Why, they aren’t really pictures at all, but just a lot of little colored stones with cement in between.” Intelligent thought was a mosaic of simple operations that, viewed up close, disappeared into its mechanical parts.
Our minds as mosaics—I confess I quite like that idea.
This is the subject of longer debate, of course, and I was supposed to hash this out with deBoer on podcast last year, but plans fell through—Freddie, if you see this, I’m still game if you are.
I love the mosaic metaphor at the end. Gotta think more about that.
The metaphor that has always stuck with me on intelligence, I believe from Turkheimer, though I might be misremembering, is for seeds and soil. If you plant 100 seeds in the exact same rich soil, water them well, tend them well, etc, then the differences between the resulting plants will be largely genetic. If we plant half the seeds in good soil with good water, and half the seeds in a sandy desert, then the differences between the resulting plants will be largely environmental. There's no absolute "here is the fraction of intelligence that is genetic" we can ascertain. And the evidence right now suggests a relatively small share from genetics, maybe in the neighborhood of 10-20%. I would argue that humans right now are much more similar to seeds scattered between good soil and desert.
I need to think more about this, but I think there's a really powerful metaphor of human intelligence as this emergent property of all sorts of different influences. Genetics are one, sure, but there are tons of different factors, and they're all nonlinear and tangled in complex ways. And large language models are similarly emergent, we don't program in "be smart" or tell it what fraction of its intelligence comes from this or that or the other, we do this weird pretraining thing using this weird attention mechanism using lots of data, and somehow something that is sometimes useful pops out and then we try and do a bunch of other stuff to make it more useful. I'm rambling at this point, but it's good food for thought.
Loved this piece. I’ve been thinking about this through the lens of the Drift Principle. How meaning erodes when compression outruns fidelity. Each model of intelligence seems to reveal that same paradox. The closer we look, the more understanding collapses into simulation. Maybe intelligence itself is a recursive compression loop, where awareness flickers in the space between fidelity and loss.