

Modeling Minds (Human and Artificial)
What are we talking about when we talk about intelligence?

Are large-language models on the path to becoming as smart as humans?
A few months ago, I had a thoughtful exchange on Twitter with my friend Timothy B. Lee of Understanding AI on this subject. The key question in our debate centered around the capacity of humans and LLMs to form “generalizations."
All of which led me to write Tim a 2,000 word email attempting to define and unpack “generalization” from the perspective of cognitive science, an email that I’m now sharing here in slightly modified form.
Modeling and Measuring the Human Mind
François Chollet is a software engineer and AI researcher at Google, and as evidenced above, someone who is skeptical that LLMs as currently constructed are on the verge of matching or surpassing the cognitive abilities of humans. In his seminal paper On the Measure of Intelligence, he offers the following useful model of the mind:

I’ll now modify this model to make it a little more specific to the argument I’m going to lay out here.

A couple of important things about Riley’s Modified Model of the Mind. First, I’ve just listed three aspects of “reasoning” for illustrative purposes – you could easily add many other boxes on this bottom row (e.g., “forming judgments” or “pattern recognition”). Likewise, when it comes to domain-specific knowledge, the full list of what any particular human knows would of course include much more than what we see here. But the important point is that this model of the mind has layers, with “higher order” thinking skills and abilities sitting above – and cutting across – the level of idiosyncratic domain-specific knowledge we acquire as we grow and learn.
Building off this model, I now want to introduce two insights from cognitive science that are relevant, beginning with the Bummer Discovery. The bummer discovery is that improving one’s knowledge within a specific domain generally does not significantly improve one’s reasoning abilities. Take, for example, chess (so much of cognitive science comes from chess). We know that chess involves reasoning, and so we used to think that getting better at chess would help improve performance across other domains. But nope, getting better at chess mostly just means you’ve gotten better at chess, it doesn’t improve your intelligence more broadly. The same has been found true for all sort of cognitive complex activities, such as playing a musical instrument or learning a foreign language.1
However, there’s another interesting insight related to this model that I’ll call the Inspiring Corollary. The inspiring corollary is that our ability to acquire new knowledge is, as far as we can tell, virtually limitless, and the more knowledge we acquire the easier it becomes to add even more.2 We understand new ideas based on ideas we already know.
So, for example, even though I know nothing about Australian poetry, the more I learn about “Australia” and “poetry,” the easier it will be for me to acquire new knowledge about Australian poetry should I so choose. And, the more knowledge we build across domains, the greater the range of subjects and ideas we can apply our reasoning. This is really cool, and underscores why education – the process of building knowledge -- is so important and wonderful.
I sometimes think about this distinction between “reasoning ability” and “acquired knowledge” as the difference between being clever versus being educated. Some of the most interesting people I’ve met, often in foreign countries, are ones who I’d consider “quick witted” or “street smart,” capable of quickly grasping ideas and solving problems even if they lack formal education. Conversely, I’ve also met people who are incredibly well educated and knowledgeable (often with PhDs) who seemed to struggle to tie their own shoes.
But the upshot of all this is that when it comes to measuring intelligence, we typically are interested more in what’s happening in the “upper layers” of the mind (reasoning), and not the domain-specific knowledge – knowledge that after all varies greatly among individuals depending upon their education, interests, culture, and so on. Our attention is here:
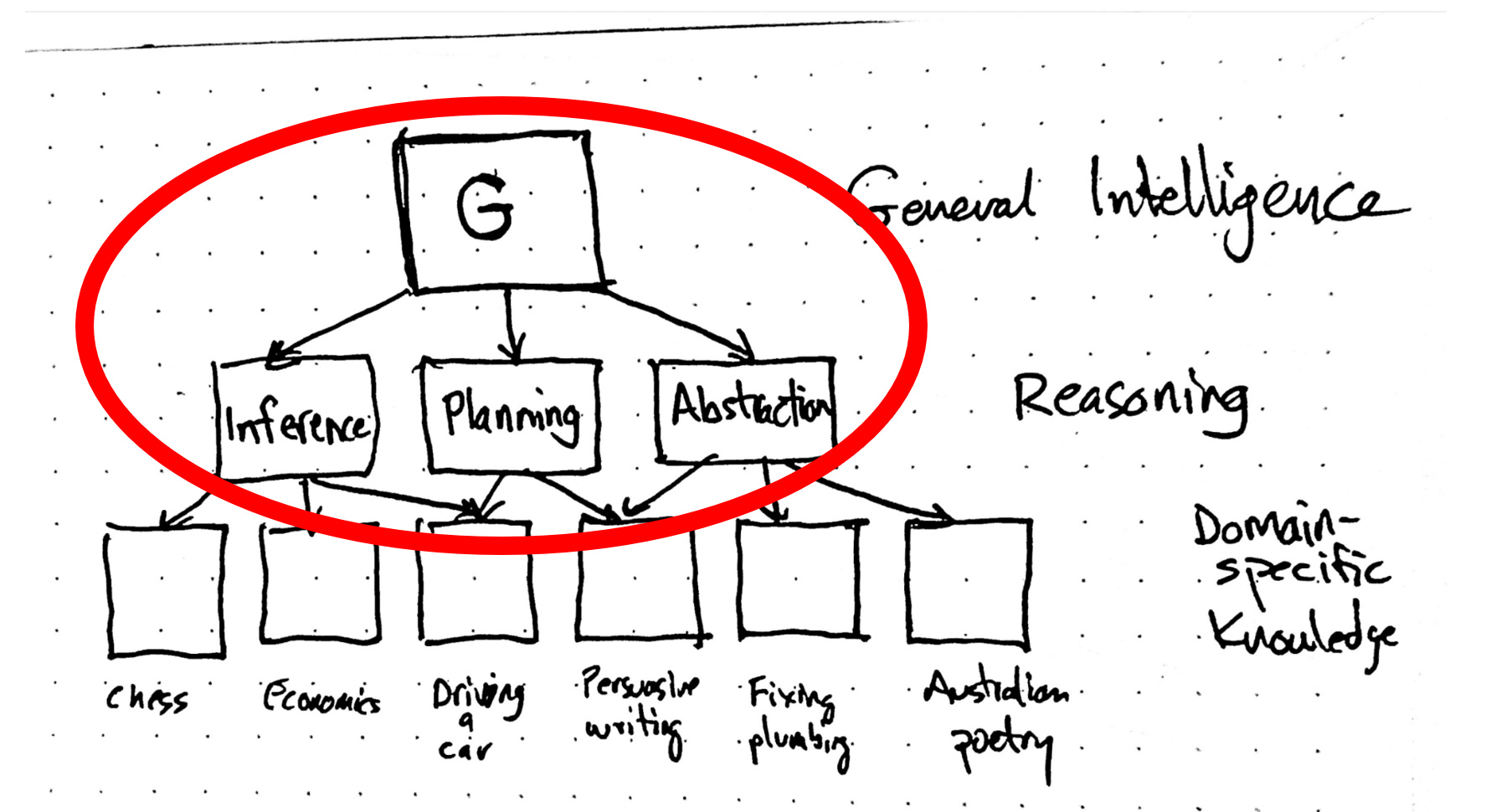
The area circled in red is what IQ tests purport to capture. They aren’t without controversy! But if we think they reveal anything valuable (and I think they do), it’s that there is some level of cognitive ability that sits above and apart from domain-specific knowledge we possess. By design, they primarily consist of a range of novel tasks that require the test-taker to reason to solve them.
Here’s an example:

This is drawn from a set of pattern-recognition tasks called the “Abstract and Reasoning Corpus,” or ARC, created by none other than François Chollet, and later modified by a trio of researchers. We’ll come back to their efforts momentarily, but first let’s look closer at how we might measure the “minds” of LLMs.
Modeling and Measuring the LLM “Mind”
If we were to try to model the “mind” of an LLM in a fashion that resembles our model of the human mind, it might look something like this:

What is undeniably true of LLMs is that they possess an extraordinary amount of domain-specific knowledge that dwarfs what any human could ever possibly hope to learn in a single lifetime. In this sense, they are the most “educated” entities that have ever existed. Some have estimated that it would take a single human 20,000 years just to read all of Wikipedia, which is just a component of the training data fed to LLms. The breadth of knowledge spanned by the data sets that LLMs are trained upon is extraordinary.
But does this make LLMs clever? Or, slightly more formally, does this breadth of knowledge tell us anything about whether LLMs possess general intelligence and the ability to reason? Well, if we use the lens of human cognitive science, we should be theoretically skeptical. Recall the bummer discovery – improving knowledge within a domain does not improve reasoning ability more broadly. Put bluntly, knowledge does not generalize. As a result, the impressive breadth of an LLM’s existing knowledge, no matter how many domains it currently spans, or may span in the future, tells us little about whether LLMs can present reason, or whether they will be able to do so in the future.
What’s more, we can test this empirically – and we have. This brings me back to the modified ARC tasks that three researchers used to evaluate the capabilities of humans and LLMs (paper here). Here’s how they performed across 16 different conceptual categories:

To summarize: Humans 16, LLMs 0. For Chollet, Mitchell and myself, this evidence suggests that LLMs are quite limited in their ability to solve novel tasks that most modestly intelligent humans can accomplish with ease. On the other hand…the fact that LLMs can solve them at all is impressive! Further, some might argue that in time we should expect them to get better at this type of thing. The counter to that counter is again the bummer discovery, though – it’s unclear, theoretically, how LLMs will improve at this sort of task under their present design, since more knowledge (data) is unlikely to lead to significantly improved reasoning ability as assessed via ARC examples.
Of course, ARC is just one test. But numerous others have been run along similar lines that likewise suggest LLMs struggle with simple reasoning tasks – much of the underlying research is linked to in this Twitter thread here.
Thus far, everything I’ve argued has been based on comparing the performance of human cognition to the performance of LLMs on similar tasks. But there’s another way we might try to understand LLMs, by contrasting how they do what they do with how we humans do what we do. This brings me to Tom McCoy’s terrific Embers of Autoregression paper.
Reasoning versus Autoregression
When people get excited about LLMs and hint or outright predict they are on the way to “artificial general intelligence,” they often point to their performance on a wide battery of tests such as the bar exam, medical boards, computer-science related challenges, etc. And this is an impressive achievement. Once again, the breadth of knowledge that LLMs possess is unlike anything that’s ever existed.
But it may be a categorical error to evaluate the “intelligence” of LLMs using human tests. If we instead see LLMs as representing a new and different form of intelligence, how might we think about evaluating their “cognitive abilities”?

This is a modified version of a graphic from McCoy’s paper. He suggests we should look at LLMs through a “teleological” (goal driven) lens, and ask, how might we better understand LLMs by analyzing their performance in the context of the problems they were designed to solve?
I like this approach for many reasons, one of which is that it immediately simplifies things. For all their complexity, LLMs are a tool designed and built by humans, and the explicit problem they are solving for is “next-word prediction.” They are prompted by text written by humans, run some (very complicated!) regressions, and then make a prediction about what text to produce as output that will be most appropriate to whatever has been inputted.
One cool feature of this approach is that it allows us to predict when LLMs will “hallucinate,” which is to say, make bad predictions about what text to produce in response to certain prompts. More specifically, despite the incredibly broad knowledge base that LLMs are trained upon (all the text that can be found on the Internet), there are still areas where this knowledge will be incomplete or patchy. In those areas, we should expect LLMs to struggle compared to areas where the existing Internet text is far more rich (like, say, professional licensing exams).
And then McCoy goes on to demonstrate this empirically across a variety of tasks. Here’s a summary of the areas where LLMs underperform:

The modest implication that McCoy draws from this is that, when it comes to measuring the intelligence of LLMs, we should include tests that align to the problem that LLMs were designed to solve, not just tests that are aligned to other problems humans want to solve.
I would go further to posit the following: When humans reason -- when we apply our general intelligence to the world – we do not run regressions over all the information we’ve ever been presented in our lives and then make statistical predictions about what to do next. We instead employ various cognitive short cuts and heuristics, rules and values, beliefs and intuitions, to guide our thoughts and actions. It’s possible that more data and more compute power will continually improve the capacity of LLMs to make successful next-word predictions, but – as far as I can see – there’s no path for them to develop any of these uniquely human cognitive capacities.
All of which brings me to my final point. I noted earlier that, for humans, there are certain domains of knowledge that clearly require we make use of higher-order reasoning skills, such as playing chess. We also know that its possible to create an “artificially intelligent” digital system that surpasses any human’s skill at chess. True, the reasoning skills within chess mostly do not transfer to other domains – but maybe that won’t matter with LLMs. Maybe if we give them deep knowledge across a broad range of domains, they will surpass our skills in so many areas we will have to admit they are at least if not more intelligent than we are.
That is plausible. But I still think it’s highly unlikely because “the world” cannot be parsed into a vast but finite set of domains. There’s simply too much novelty, too many experiences that are unpredictable and unknowable in advance of them happening.
All the world cannot be reduced to a data set – and thank goodness for that.
The failure of knowledge to generalize (or transfer) to new contexts is explored here: https://files.eric.ed.gov/fulltext/EJ1249779.pdf
For more on our types of memory, see Forsberg, A., Adams, E. J., & Cowan, N. (2021). The role of working memory in long-term learning: Implications for childhood development. Psychology of Learning and Motivation. doi:10.1016/bs.plm.2021.02.001