

Measuring Artificial IQ
The newest model of ChatGPT smashes records, but what does it mean? PLUS: Love and Ethics and AI Skepticism

POP QUIZ! I’m going to show you three before-and-after pictures (labelled “input” and “output”), and then I’ll give you a task to solve. First:

Second:

And third:
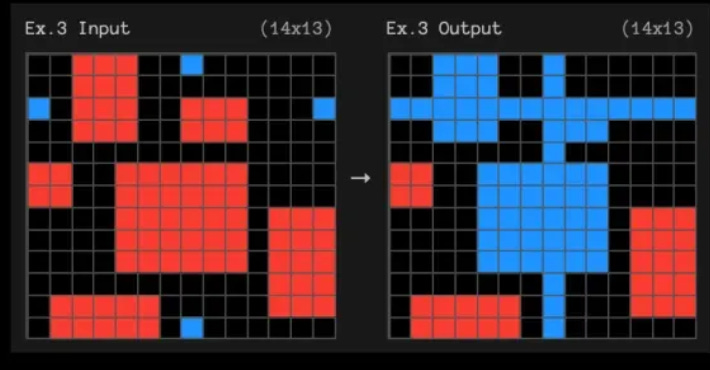
Ok, now you’re ready for the exam. Below, there’s a before…what should come after?

I am inserting a break here solely because I really want you to look at these examples and think about this before you continue reading.
Ok, now we can move on.
You got it, right? Well done. My guess is you figured out that you should draw horizontal and vertical blue lines connecting the blue boxes on the sides of the grid, and then change the color of any red boxes that the blue lines pass through to blue. Something like this:

Also, congratulations—you just completed a test item from the “Abstract Reasoning Corpus,” or ARC Prize, created by François Chollet, a scientist who until recently was at Google DeepMind. ARC is an intelligence test for both humans and AI. Immediately we tread into controversial waters, but for the moment, let’s put those aside and focus (briefly) on what just happened when you read through the examples I provided above. My hunch is that you quickly recognized the pattern common to the three before/after examples, and based on that, you inferred the rules governing the transformation process. And, you were able to do that despite the fact that, unless you live a very strange life, you surely do not spend most of your days connecting colored boxes in tiny grids. Which is to say, you were able to abstract the rules from just a few examples, and use reason to apply them a new situation (the final task). Abstract. Reasoning. Corpus. The name is apt!
The ARC test, and Chollet himself, are big deals in the AI research world. This is in part because Chollet created this intelligence test years ago as a means of comparing human-to-AI reasoning abilty. What’s more, Chollet has been very outspoken about the limitations of large-language models in being able to handle novel tasks that fall outside of the data sets they’ve been trained upon. Indeed, in one of the very first essays published on this Substack back in March 2024, I cited the poor performance of LLMs on ARC as reason to be skeptical these tools were tracking toward “artificial general intelligence” given that LLMs could only solve 5-25% of ARC tasks at that time, compared to 85% for the average human. And just to really put myself out on a limb, I further noted that “it’s unclear, theoretically, how LLMs will improve at this sort of task under their present design, since more knowledge (data) is unlikely to lead to significantly improved reasoning ability as assessed via ARC examples.”
Oh how things can change.
In late December 2024, OpenAI announced that its newest “reasoning” model, GPT o3, had shattered all previous records for LLM performance on ARC, scoring between 76% to 87%. It reached human-level performance, in other words. This may have something to do with Sam Altman triumphantly declaring that artificial general intelligence is basically a solved probem. We can dismiss that as corporate hype, but we cannot (and should not) so easily dismiss Chollet’s evolving opinion, given his longstanding critiques of LLM capabilities. And in his view, the o3 performance on ARC was and is a very big deal:
These numbers aren't just the result of applying brute force compute to the benchmark. OpenAI's new o3 model represents a significant leap forward in AI's ability to adapt to novel tasks. This is not merely incremental improvement, but a genuine breakthrough, marking a qualitative shift in AI capabilities compared to the prior limitations of LLMs. o3 is a system capable of adapting to tasks it has never encountered before, arguably approaching human-level performance in the ARC-AGI domain.
Gimme a second. Deep breaths. The sound you’re about to hear? That’s me, moving some goal posts.
So here’s the deal: If it is true that these so-called LLM reasoning models can in fact reason, that is a big deal—and those of us who consider ourselves AI skeptics should not be willfully blind to empirical evidence suggesting otherwise. But we don’t yet know how o3 achieved these results on ARC. You may have started to hear the phrase “inference-time compute” buzzing in AI circles, which (broadly speaking) represents a shift away from improving models simply by hoovering up more data, and toward improving performance by having models generate a bunch of additional text during the process they undertake to produce their final output. We try to avoid anthropomorphism around here, but it’s reasonably fair to say these “reasoning” models make their “thinking” explicit and that, for reasons that are still not well understood, this significantly improves their capabilities.
I know, that’s a lot. Hope you’re still with me. Here’s the first key point, though—as Melanie Mitchell contends, what matters is not just whether LLMs can solve ARC tasks, but how:
Is o3 (or any of the other current winning methods) actually solving these tasks using the kind of abstraction and reasoning the ARC benchmark was created to measure?The purpose of abstraction is to be able to quickly and flexibly recognize new situations using known concepts, and to act accordingly. That is, the purpose of abstraction—at least a major purpose—is to generalize….Machine learning methods are known to “overfit” to specific cases and often aren’t able to generalize well…
I have similar questions about the abstractions discovered by o3 and the other winning ARC programs. These questions can be answered in part by further testing: seeing if these systems can adapt to variants on specific tasks or to reasoning tasks using the same concepts, but in other domains than ARC. The questions can also be answered by studies on the systems themselves: understanding better how they work under the hood, and how well they can explain their own reasoning processes using the kinds of abstractions for which the benchmark is supposed to be a general test.
I think Mitchell is exactly right, but properly testing these models is a real challenge, since they are owned and operated by private corporate actors. It’s hard to get under the hood when the garage is locked.
The second key point is that, even as we sit here today, there’s already reason to be skeptical that o3 performance on ARC represents a truly transformative breakthrough in artificial intelligence. Why’s that? Well for one, as machine-learning researcher Mikel Bober-Irizar observes, LLM performance on ARC is highly correlated with the amount of pixels involved in the puzzle! The bigger the grid and the more shapes there are, the worse LLMs do, including o3:

In contrast, human performance is barely affected by pixel size:

Bober-Irizar goes on to note that part of the problem is that LLMs do not “see” the grids the way that humans do, and they (the LLMs) can only tackle these tasks through an awkward process of converting them to text-based matrices. As a result, “ARC is acting as a ‘grid perception and transformation’ benchmark as well as a general reasoning/intelligence benchmark, and thus might overstate some improvements and understate others.”
But that’s not all. There remains the ongoing fact that existing LLMs continue to produce output that does not accord with our understanding of what is “true” in the world. Call this hallucination, call it confabulation, LLMs exhibit (at most) what Gary Marcus is now calling BSI, for Broad, Shallow Intelligence—meaning, they can regurgitate human knowledge without necessarily possessing a deeper understanding of what words mean. I like the acronym and hope it catches on.
Here you might reasonably ask, but what does that mean, “deeper understanding”? This, finally, brings us to the big questions looming over all of intelligence testing, namely, whether IQ tests are indicative of something important other than the test itself (aka “construct validity”). In drafting this essay, I reached out to my friend Sean Trott, a cognitive scientist and leading proponent of using empirical methods in pursuit of LLMology (that is, an understanding of LLMs), to get his take on the implications of o3 and ARC:
Many people view ARC as a good assessment of general intelligence, and I think I understand their argument from a face validity perspective, but for me there's still some residual concern about its construct validity. As in: what kind of empirical (or theoretical) confirmation do we have to reassure us that the ability (or lack thereof) to solve this task is a good reflection of, say, AGI?
With human IQ tests—themselves, obviously, a controversial subject, which I'm certainly not an expert on—I believe proponents typically point to: a) test-retest reliability; and b) predictive validity, i.e., their empirical correlation with things like income/earnings and such, as well as other more "cognitive" tasks. Even with that evidence I'm uncomfortable issuing strong claims about what those measures tell us about humans, which maybe accounts for why I'm reluctant to draw inferences about what similar measures tell us about LLMs.
At the end of the day I do think an LLM's ARC score (good or bad) carries some information. I am just still uncertain about what—and in general my view is (unsurprisingly) that uncertainty is probably the right stance here, but I could probably be convinced one way or the other.
The question of what IQ tests actually tell us about ourselves will be a theme of Cognitive Resonance in 2025, especially against the rising tide of overt racism and neo-eugenics taking place across society. There’s a throughline from the past to the present. But for now, just remember: o3 might be significant, but the robots have not become sentient. I promise.
Love and Ethics and AI Skepticism
In December, I published Who and What Comprise AI Skepticism?, a taxonomy of many of the leading thinkers poking holes in the AI hype machine. It was a hit. It’s been my most read essay (by far), and it seems to be undergoing a sort of continued virality, if that’s a word.
I wrote my piece in response to an essay by Casey Newton of Platformer and Hard Fork fame that also purported to describe AI skepticism. At the time, I thought his essay was oddly crafted and poorly sourced—it felt like a drive-by description of AI skepticism, rather than a thoughtful examination of who and what it entails. But, you know, whatever. Newton covers all of tech, not just AI, and if he wanted to write a cursory overview of the space—and attack Gary Marcus in doing so—that’s his choice to make.
However. My ears perked up last week when Newton disclosed, via his newsletter and on his podcast, that he’d fallen in love over the past year, and that his boyfriend, as of January 7, 2025, had started a new job…as a software engineer at Anthropic.
A couple of thoughts here. First, congratulations to Newton—falling in love is obviously one of life’s purest joys, and I’m truly happy he’s found someone.1 Second, kudos to Newton for disclosing this relationship and acknowledging the potential conflict it poses. Among other things, going forward Newton plans to disclose his relationship on anything he writes “that primarily concerns Anthropic, its competitors, or the AI industry at large.” (My emphasis; source here.)
That’s going forward, though—what about looking back? Here’s the thing: When I learned about Newton’s relationship, my immediate thought was, “huh, perhaps that explains the strange AI skepticism essay he wrote.” Newton’s piece ran on December 4, 2024, so unless Anthropic has a lightning fast hiring process (which is possible), it seems likely that Newton knew his boyfriend was seeking employment there when he (Newton) was drafting his essay that in my view mischaracterizes the very community that is criticizing companies such as Anthropic.
Likely…but not certain. On last Friday’s Hard Fork podcast, Newton invited listeners to email him if they had any questions about his relationship and his coverage of the tech industry. So I did, and asked if he knew his boyfriend was applying or interviewing with Anthropic when he wrote his AI skepticism piece. He first responded with the following:
As I mention in my disclosure, Anthropic had no knowledge of our relationship during the entire application process. Had I disclosed that my boyfriend had applied for a job at Anthropic before he had even been interviewed, it would have been viewed as a terribly unethical use of my own position to interfere with the hiring process.
That wasn’t my question, so I clarified and asked again about what Newton knew, and when, regarding his boyfriend’s career plans. He responded:
Why does that matter to you, and why do you think it's in the public interest to know?
I responded by noting that drafting and publishing an essay that was critical of AI skeptics at the same time his boyfriend was pursuing a career with a leading AI company created at least the appearance of a potential conflict—after all, this is why Newton is disclosing his relationship now (admirably, I say again). In my view, the same ethical question applies retrospectively, so for a third time I asked him to clarify when he knew about his boyfriend’s professional pursuits.
Newton never replied back.
Is any of this unethical? I don’t know, it feels like a gray area, and the New York Times’ ethical guidance is hazy on “sorting out family ties.” But maybe the bigger question goes to Newton’s journalistic credibility. As David Karpf observed, Newton’s AI skepticism piece felt like an outlier to his (Newton’s) typical output:
His reporting is generally excellent. He is well-sourced and tenacious. He has developed a solid bullshit-meter when dealing with crypto folks and Musk acolytes. His Hard Fork podcast is great. But I think he’s missing the point here. And there’s some real depth to what he’s missing.
I agree. Love may or may not be blind, but let’s hope it doesn’t put blinders on Casey Newton’s future coverage of AI skepticism.
Fun fact: I also found love last year, and via this Substack no less—seni seviyorum, my cevherim.
Way to go after a comment from Newton! Substack journalism on the rise.
Appreciate the critical analysis of the o3 performance on ARC. That news hit over winter break without much impact and it feels like the press has moved on from o3...those stories about falling in love with a chatbot don't write themselves, you know.
I was left confused, and this got me straight. Thanks!