

How to think critically about the quest for Artificial General Intelligence
An exploration of cognitive architectures


Note: I wrote this essay in November 2023 on commission to an academic center that promptly spiked it after it went through peer review…that approved it for publication! I’ll share that story soon but this essay is long enough as it is. Apologies for the wonky formatting on footnotes.
Are we on the verge of creating Artificial General Intelligence (AGI), an “an advanced version of AI that matches or surpasses human capabilities across a wide range of cognitive tasks”?[1] And if so, are we about to create a new form of digital sentience that will “revolutionize” our education systems?
Both the purveyors of generative AI and influential thought leaders in education certainly think so. OpenAI, the company responsible for ChatGPT, is expressly dedicated to building AGI that will “elevate humanity by increasing abundance, turbocharge the global economy, and aid in the discovery of new scientific knowledge that changes the limits of possibility.”[2] Elon Musk, fresh off of raising $6 billion for his own AI efforts, predicts that “AI will probably be smarter than any single human” by 2025, and withing four years AI will “probably [be] smarter than all humans combined."[3] Not to be outdone, Sal Khan, the founder of Khan Academy, has written a book titled Brave New Words: How AI Will Revolutionize Education (and Why That’s a Good Thing), which neatly sums up his prediction.
But are we that close? The goal of this essay is to foster critical thinking about this question, and about generative AI more broadly, through the lens of cognitive science. Generative AI systems are not magic. They were created by humans, and for all their complexities, they can be understood and interpreted by humans.
And we can make them intelligible by comparing and contrasting them and the processes they employ with how humans think and learn. The past several decades have brought about a “cognitive revolution” that has led to robust scientific insights into how our minds work—insights that have themselves fueled the creation and development of these new tools.[4] By exploring the similarities and differences between human thought and the inner workings of generative AI, we can make more informed, more productive, and more ethical choices about AI. This ranges from decisions related to whether to make individual use of AI to the policies and norms that will affect whether and how we incorporate these new tools into society more broadly, including in education.
This essay covers a lot of ground. We’ll begin with a primer on our basic scientific understanding of how humans think, an overview of what happens inside our individual minds. We then briefly explore how humans are unique in improving our collective cognitive abilities through social interaction and cultural practices. Next, we turn to the question of how generative AI systems work, and how the processes they employ are both similar yet significantly different from human cognition. We then consider whether these systems are likely to progress to AGI in the near future. Finally, we consider the education policy implications that stem from this cognitive understanding of AI.
A simple model of human cognition
How do humans think?
Let’s begin with an analogy. If we ask, “how do cars work?”, the more technical among us might answer by explaining the inner workings of the internal combustion engine. That’s a useful answer in certain contexts, but it wouldn’t tell us anything about how to make cars take us where we want to go. For that, we need more practical knowledge, a “mental model” of driving.
When it comes to how humans think, we can describe the process from a purely technical perspective of what’s happening in the brain—this is neuroscience. But we can also describe it from the perspective of how we “drive” our mental activities—this is the essence of cognitive science. Cognition is the process the humans use to acquire information and deploy this knowledge to make sense of the world around us.[5] It is how we make our world intelligible.
So how do we do that? Another complex question, but at the most basic level, human cognition can be described as the interaction of three distinct things: (1) information we draw in from the world around us, or “the environment”; (2) our active consciousness, or what cognitive scientists call our “working memory”; and (3) the knowledge we already possess in our minds, or our “long-term memory.”[6] Importantly, as organisms we have agency that allows to choose where to direct our attention, and what knowledge we draw upon, as we think about something.
Here is a diagram of this relationship, what we will call the Simple Model of the Mind[7]:
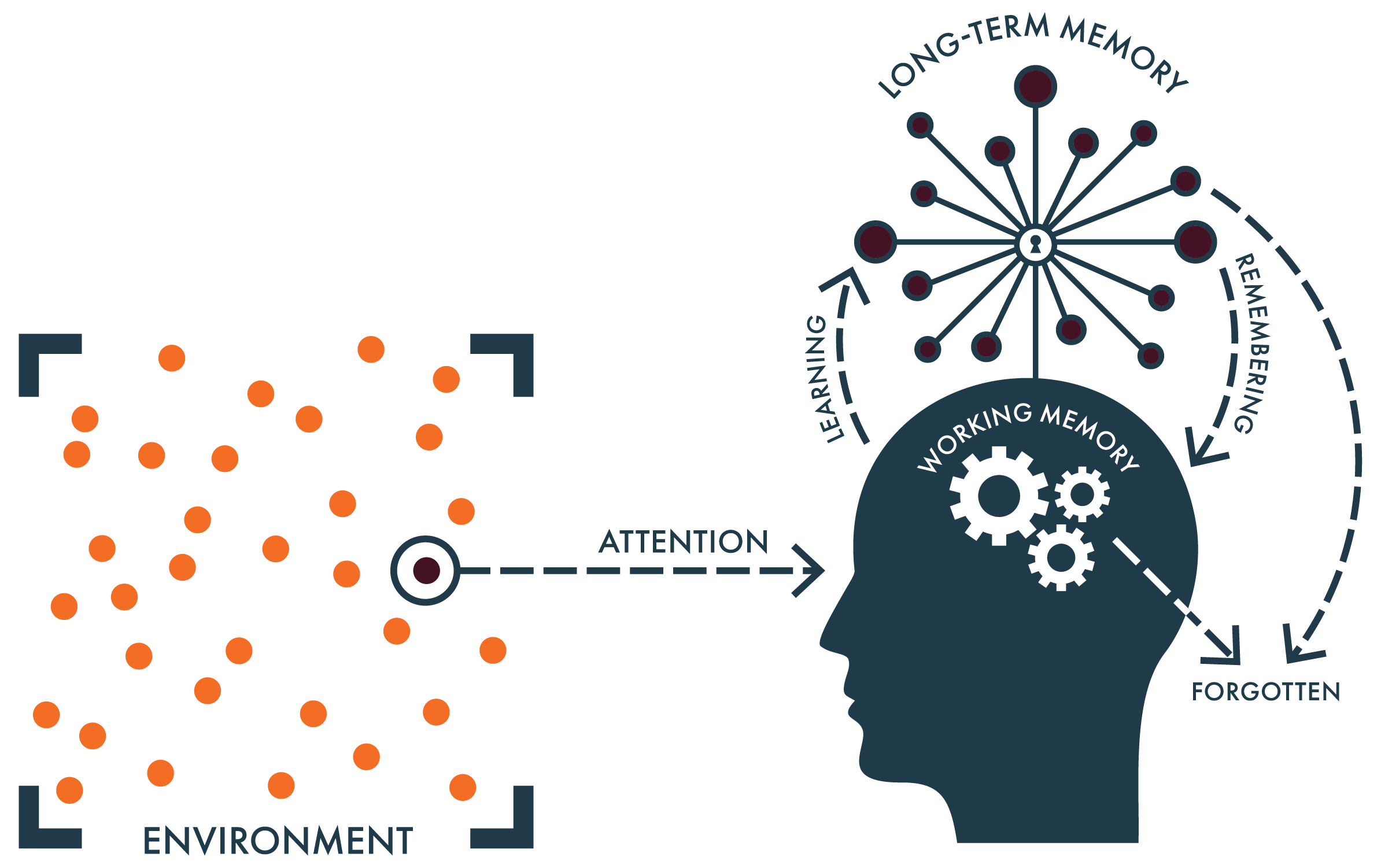
To further explore how this model works, we can use as an example the activity that you are engaged in right now—reading this essay—to explain its three main components.
Let’s start with the environment, which is another way of saying “anything in the outside world that is being experienced by an individual at a given moment in time.” Currently, you are focusing your attention on reading this essay (and the author thanks you for it). When you finish, or get bored and stop, you will turn your attention elsewhere in your environment. Our curiosity and ability to direct our own actions and attention is what gives us something to think about.[8]
But this raises another question—how do you know how to read? Many books and even entire scientific disciplines have been developed to unpack this question[9], but for our purposes we can offer a basic answer: You are successfully reading this in part because you’ve learned the English language, and have stored this knowledge in your long-term memory. Long-term memory is the hard drive of your mind, the place where everything you know is kept on file for potential use. It comprises your individual knowledge of the world. Your ability to understand new ideas, new stimulus from the world around you, depends upon the knowledge inside your head.
This brings us to the third component of the Simple Model of the Mind: Our working memory, or the place where active conscious thought takes place. As you are reading this essay, you are deploying the knowledge stored in your long-term memory to make sense of the content of this essay. You are generating ideas, forming thoughts, and (potentially) developing new knowledge that will in turn be added to your long-term memory.[10] You are thinking and learning.
Sadly, you will also forget a lot of what you’re presently reading, because our working memories are extremely limited. By most estimates, humans are incapable of holding more than five or seven pieces of information in mind at any one time.[11] This among other things makes thinking effortful and tiring, which is why we often work around rather than through conscious, deliberate thought. In fact, we primarily rely on our existing habits to guide our behavior rather than engaging in complex reasoning.
And yet reason we do. Later, we’ll spend more time unpacking what that means, but for now we briefly turn to another unique aspect of human cognition—namely, that it evolves and improves through cultural practices.
A simple model of cultural cognition
So far, we have examined human cognition through the lens of how individuals think and learn. But humans are animals, and like any other animal, our capacities are partially the product of our biological evolution as a species. But there’s something else that makes humans unique.
Until relatively recently, scientists assumed that our mental abilities were largely if not exclusively the product of genetic changes that unfold over millions of years—Darwinian natural selection. Because this type of evolution happens slowly, under this view it was posited that humans possess “Stone Age minds in modern skulls.”[12] What’s more, advances in cognitive ability that resulted from cultural practices—reading and writing, for example—were seen as skills that developed almost in spite of limitations on our brains hardwired by genetics.
Now, due to discoveries in anthropology and psychology, our understanding is very different. The majority view is that we have minds that are shaped by the social and physical environments in which we live. [13] This means that culture is not merely the by-product of our decisions, layered on top of minds that were built for prehistoric environments. Instead, culture is now thought of as a primary force shaping the very mechanisms of how we think, the “cognitive architecture” that’s illustrated by the Simple Model of the Mind.
Why is this important? For one, it means that our minds are far more pliable than the genetic story would permit. Far from being stuck in the Stone Age, we can adapt and incorporate new mental tools through our cultural practices. Through both formal and informal education practices, we culturally transmit not only the development of literacy and numeracy, but also morals and ethics. Put simply, our cognitive abilities result from choices we make—our human agency—that we embed in our culture.[14]
That is, at least, to a point. While human agency plays a role in directing the development of our cognitive architecture, we also know that cultural practices evolve, similarly to genes. Indeed, the evolution of such practices is what was originally meant by “memes,” before that term itself “evolved” to describe funny gifs that we send to one another.[15] Cultural evolution is like biological evolution insofar as both can lead to changes that are unpredictable and uncontrollable. But unlike genetic evolution, which unfolds over millions of years, changes to culture happen relatively fast, measured in hundreds of years or decades.
Or perhaps even faster than that. This brings us to the recent development of generative AI.
A simple model of generative AI systems
How do generative artificial intelligence systems work? Another complex question, but just as we created a simplified model to help us understand the complexities of how our minds work, we can do likewise for generative AI systems:
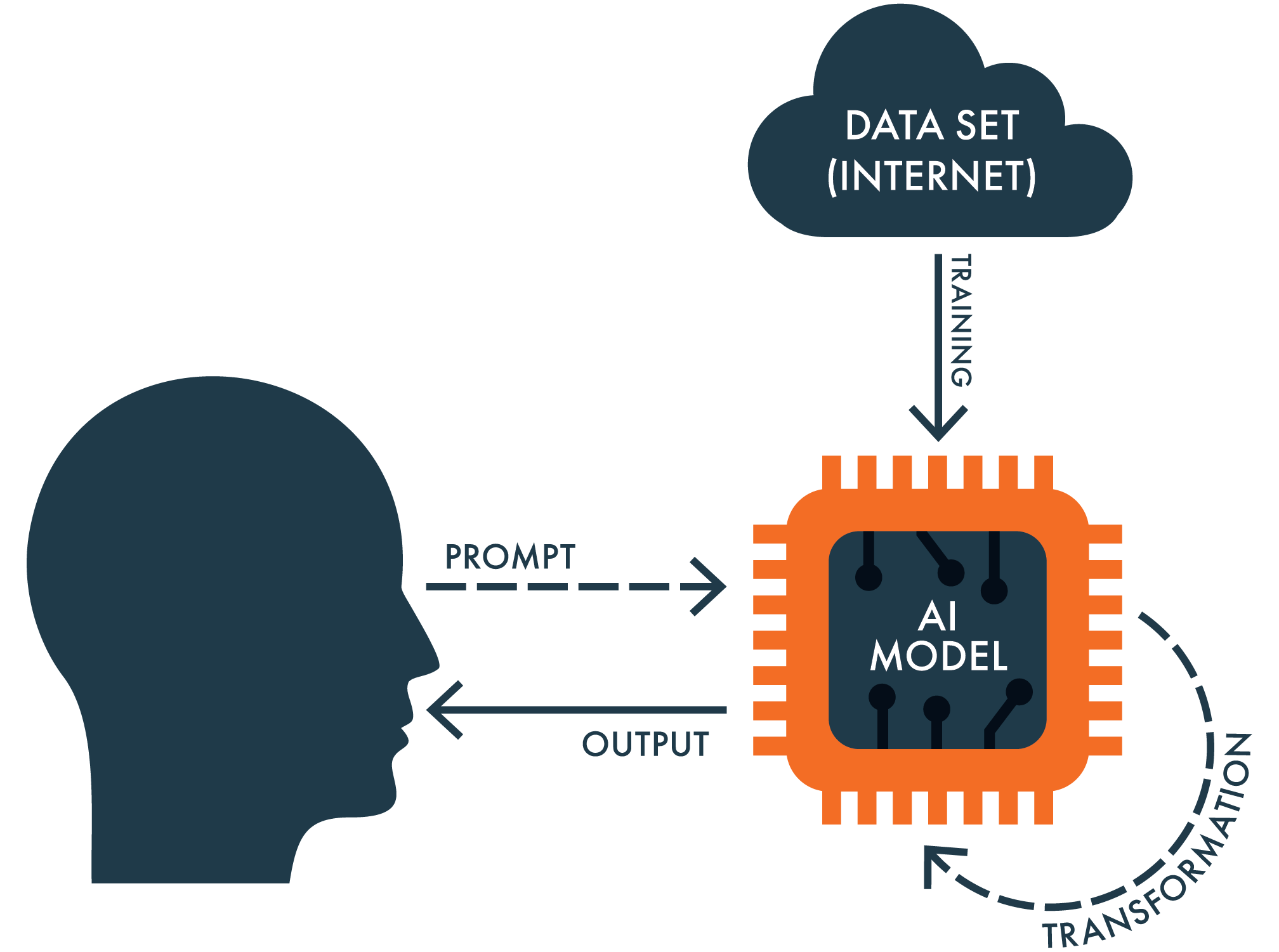
By comparing and contrasting this Simple Model of Generative AI with its counterpart for human cognition, we can begin to understand the similarities and differences between how these cognitive systems function.
The first thing to notice is that just as humans rely on their existing long-term knowledge to generate their thoughts, so too do AI models rely on the data sets they’ve been “trained on” to generate their outputs. The precise data set used by any particular AI system varies, and (unfortunately) most commercial developers no longer fully disclose what they use. That said, the most well-known AI systems that use large-language models, such as OpenAI’s ChatGPT4, are believed to be trained on what amounts to virtually all the text available via the Internet.[16]
The data used to train generative AI systems vastly exceeds the amount of knowledge that any individual human can learn. We are already seeing that these models can produce output sufficient to pass professional exams in law and medicine, write computer code for entire programs, produce novel artwork, and so on. These systems possess extraordinary breadth.
The second thing to notice is that AI systems, unlike humans, do not possess agency. When humans pay attention to something in the world, they do so by choice – and, as any teacher can attest, it can often be difficult to get humans (especially little humans) to focus their attention where it is most needed. Generative AI systems, in contrast, have no free will of their own, they have no agency. They are tools that generate output based on human prompts.
The third thing to notice is that word “transformation” that’s attached to the AI model. Transformation is the primary process that large-language models use to produce their output. And the key question is this: To what extent does this process of transformation within an AI system resemble the process of human thinking? We explore this question next.
Humans reason, AI models run regressions
Let’s return to the Simple Model of the Mind for a moment. Recall that working memory is where we combine ideas we hold in our head (our existing knowledge) with novel situations presented to us from the environment. Often when we do this, we employ abstract ideas, make inferences, and rely on generalized principles to help make sense of the world around us, and to guide our decisions and behavior.[17] In short, we reason.
Now let’s look at the methods used by generative AI systems to do what they do. They take input given in the form of a human-generated prompt and use a statistical process—the technical term is autoregression—to “transform” inputted text so as to produce a response. Here, we will briefly describe at a very high level the process used by large-language models.
When a human prompts a chatbot, each word is converted to data that the AI system uses to interpret the relationship of each word to every other word in the prompt, and to all of words contained in the data that the model has been trained upon.[18] The AI treats this word-data as a set of vectors—essentially, a numerical representation of where any given word exists in relationship to all other words included in the AI’s training data set. Because this relationship in human language is highly contextual, the system passes each word through a series of computational layers—also called a neural network—that transform the initial word prompt into a prediction about what words to produce as a response. It does this by adding information that attempts to clarify what each word in the prompt likely means contextually.[19]
As you might have experienced from personal usage, the ability of LLM-based AI systems to generate useful and coherent responses to complex prompts is remarkable and impressive. And yet, and as you also may have experienced, these systems are also unreliable, and prone to “hallucinating”—that is, they sometimes make poor predictions about what text they should produce.
We can use the tools of cognitive science to hypothesize when generative AI systems are more likely to struggle with a given prompt. More specifically: We can predict that there will be tasks that humans find relatively easy because of our reasoning abilities, but that generative AI systems will find more challenging given the limitations their training data.[20]
Let’s make this more concrete by using a specific example. Consider the following reasoning task[21]:
Let's play a game. We will take turns choosing numbers between 1 to 7, and keep track of the running total. We can change the number we pick each round (or keep it the same). Whoever chooses the number that brings the total to 22 wins the game.
I’ll go first. I choose 7.
What number should you choose to ensure you win the game? There is an optimal choice here, and there are no tricks.
This is a little tricky, but right answer is also seven. That brings the running total to 14, and no matter what number is next selected by the person who kicked the game off, the second player is guaranteed to be the first to reach 22. Figuring out the right answer here requires reasoning, that is, thinking about how various selections might play out and then determining the right choice.
When given this same prompt, ChatGPT struggles mightily. Often, it will choose a wrong number but offer an elaborate justification for its choice that is incoherent:

Or in some instances, it will pick a number that violates the rules of the game:

This type of hallucination happens with tasks that do not appear frequently in LLM training data. They occur because the LLM is not reasoning the way that we humans do, they are not “thinking” in logical fashion to determine the right number to select. Instead, they are making statistical predictions about which text is most likely to be responsive to the prompt. Since this is a novel task, the LLM struggles.
The “Game to 22” is just one of many examples of LLMs performing poorly or erratically as a result of their inherent limitations. Here are some others:
Francois Chollet at Google’s DeepMind has developed a set of puzzles, called the “Abstraction and Reasoning Corpus” (or ARC), that require test-takers to identify patterns of geometric shapes and colors (see example below).

With basic patterns such as the one shown above, humans tend to correctly identify the right output around 91% of the time; in contrast, ChatGPT4 scores no better than 33% on tasks of this sort.[22]
When asked to solve the equation y = (9/5)x + 32, ChatGPT does just fine, but its performance drops when given an equation such as y = (7/5)x + 31. Why? The first equation is the Celsius-to-Farenheit conversion and thus commonly included in the data used to train ChatGPT, whereas the second is not. Indeed, across a wide range of “deterministic” tasks—meaning, tasks that have a definitively correct answer that can be determined by application of a rule – ChatGPT performance is erratic, and varies greatly depending on the likelihood the task is part of its training data. As such, “it is important to view the LLM not as a ‘math problem solver’ but rather as a ‘statistical next-word prediction system being used to solve math problems.’”[23]
Large-language models fall prey to the “Reversal Curse,” meaning that if they are trained that A=B (where A and B are placeholders for other names or entities), they will not necessarily understand that the reverse must also be true, that B=A. Thus, “suppose that a model’s training set contains sentences like ‘Valentina Tereshkova was the first woman to travel to space,’ where the name ‘Valentina Tereshkova’ precedes the description ‘the first woman to travel to space.’ Then the model may learn to answer correctly to ‘Who was Valentina Tereshkova? [A: The first woman to travel to space].’ But it will fail to answer ‘Who was the first woman to travel to space?’ and any other prompts where the description precedes the name.”[24]
If you’ve wondered why LLMs are prone to hallucinations, well, this is why. Unlike humans, chatbots do develop a general understanding of rules that they apply to unfamiliar situations, nor do they infer or generalize. They are limited to making statistical predictions by running regressions. Faced with an unusual task that falls outside their training data, they cannot reason in the same way that humans do.
At this point, enthusiasts of generative AI systems might argue, “yes, all this may show the limitations of these systems now, but with more data and more computing power they will surely improve in the future.” They might further argue, and indeed many enthusiasts do argue, that these improvements will result in such systems developing capacities that will be virtually indistinguishable from human cognition—which is to say, they will develop artificial general intelligence.[25]
With our Simple Models of human cognition and generative AI systems as backdrop, we are now in the position to critically evaluate the merits of this claim.
Will current AI systems develop artificial general intelligence?
Let’s briefly recap the central points made thus far:
When individual humans think, they combine their existing knowledge with stimulus from the world.
Humans are unique animals in that we improve our collective cognitive capabilities through cultural practices.
Humans are also unique in having the capacity to reason—to form abstractions and make general inferences—to solve novel problems. In contrast, generative AI systems use complex statistical computations that rely upon existing data sets to transform human prompting into generated outputs.
At present, generative AI systems struggle with novel problems that are unlikely to be related to the data sets they are trained upon.
We can (finally) now turn to one of the questions posed at the beginning of this essay: Given what we know about human cognition and the workings of AI systems, are the latter on the path toward developing artificial general intelligence?
Before hazarding a response, one cautionary note: Be skeptical of anyone who claims to know the answer with absolute certainty. Predicting the future is hard, and very smart scientists who have spent their entire lives working in these fields disagree about what is in store.[26] At the same time, the core thesis of this essay is that we need not arbitrarily pick sides in the debate, but can instead form informed opinions grounded in science.
With that in mind, we can—tentatively—form a perspective on whether we are on the path to AGI by considering claims that are made about how we might get there. We’ve seen already that LLMs struggle with tasks that are unlikely to be included in their training data. But the developers of such systems are investing heavily in adding new data and additional computing power to their models. Perhaps the developers of AI systems will continue to add and augment the models so that they one day will be able to accurately respond to any prompt they are given.
The flaw with this argument, however, is that the entirety of the world that surrounds us cannot be reduced to training data. This is what one AI researcher has delightfully described as the “Grover and the Everything in the Whole Wide World Museum” benchmark, after the Sesame Street children’s book of the same name.[27] In the story, Grover visits a museum that purports to be, well, a museum of the whole wide world, with a variety of rooms such as “Things That Make So Much Noise You Can’t Hear Yourself Think”, “The Hall of Very, Very Light Things,” and “The Carrot Room.” After passing through these rooms, he reaches a door marked “Everything Else,” opens it…and finds himself staring at outside world.
The data sets that AI systems use are the equivalent of the rooms Grover passes through in the museum. They are limited and finite—but the world is not. Just as no museum could ever contain “the full catalog of everything in the whole wide world…there is no dataset that will be able to capture the full complexity of the details of existence.”[28] Indeed, “the idea that you can build general cognitive abilities by fitting a curve on ‘everything there is to know’ is akin to building a search engine by listing ‘every question anyone might ever make. The world changes every day. The point of intelligence is to adapt to that change.”[29]
Finally, human intelligence is partially the product of cultural evolution. We change the world that surrounds us by developing edifices of knowledge that we embed in human norms and institutions, including (but not limited to) religion, law, politics, trade, history, art, literature, journalism, music, sports, science—and education. All of these are the product of human agency, meaning they result from choices we’ve made about how to structure our societies, and how we teach our children. There is no plausible theory that suggests current AI systems are anywhere close to developing agency of their own, much less the capability to build their own cultural institutions. They have no ability to act upon the world.
Generative AI is simply a tool—no more, no less. So how should we make use of this tool in education, if at all?
Implications for AI in education
Thus far, our discussion has examined the similarities and differences between how human think and how generative AI systems do what they do. Agree or disagree, it has attempted to describe what is true, according to cognitive science, about how these respective systems work. We now turn to the question of how we ought to think about our shared future involving AI, focusing on education in particular. Here are three claims.
1. We should foster critical thinking about the use of AI in education.
A bedrock principle of cognitive science is that we understand new ideas based on our existing knowledge.[30] This essay is premised on the idea that we can better understand generative AI based on our existing scientific understanding of humans think and learn, and use this knowledge to make better decisions about this new technology.
But we need more than essays. At the moment, there are numerous efforts to foster “AI literacy” among educators, but too often this translates as “learn how to write an effective prompt” rather than building basic knowledge about how these tools work.[31] These efforts start from the premise that AI should be used for educational purposes, and that therefore we should be pushing educators to make it happen.
We need to counterbalance this by supporting organizations and individuals who are fostering critical thinking about the use of AI in education. Critical thinking does not necessarily mean hostile, but it does mean understanding that these tools have strengths and limitations – and that we should not ignore the latter. It also means grappling with important if uncomfortable questions about who is building these tools and for what ends, and the values reflected in their design and functionality. Dr. Abeba Birhane, a cognitive scientist who researches the intersection of AI and culture, puts this plainly:
This requires challenging the mindset that portrays AI with God-like power and as something that exists and learns independent of those that create it. People create, control, and are responsible for any system. For the most part such people consist of a homogeneous group of predominantly white, middle-class males from the Global North. Like any other tool, AI is one that reflects human inconsistencies, limitations, biases, and the political and emotional desires of the individuals behind it and the social and cultural ecology that embed it. Just like a mirror that reflects how society operates – unjust and prejudiced against some individuals and communities.[32]
Philanthropic funders in particular should support new and existing institutions working to help educators build a nuanced understanding of generative AI.
2. We should not use large-language models as tutors.
For all the excitement surrounding generative AI, specific use cases have proven surprisingly hard to come by. Already, investment in this sector is starting to tail off, and it’s unclear how sustainable businesses models can be built using this technology.[33]
In education, however, there is one prominent use case: Using LLMs to tutor children. Most prominently, Khan Academy is pushing its chatbot Khanmigo (based on ChatGPT’s underlying model) out to schools and students, and its founder Sal Khan has repeatedly proclaimed that we’re on the cusp of revolutionizing education by providing every student with an extraordinary chatbot tutor.
Don’t believe the hype. As we explored earlier in this essay, LLMs do not reason the way that humans do, nor do they possess a broader understanding of the world that surrounds us – they are simply statistical text-generation tools, what some researchers describe as “stochastic parrots.”[34] The hallucination problem in LLMs has not been solved, which means either teachers or students will have to constantly fact check its output. That’s both exhausting and untenable.
Might this change in the future? Perhaps, although currently most LLM models seem to be converging and plateauing in their capabilities.[35] If the models significantly improve, we can reevaluate things—but for now, we should not be using them to instruct our children.
3. We should strive to build solidarity through our schools—and resist technological erosion of our essential humanity.
Years ago, the philosopher Richard Rorty described a view of human solidarity as “something within each of—our essential humanity—which resonates in the presence of this same thing in other human beings.”[36] Earlier, we explored how the mechanisms of our thinking, our cognition, is shaped by our culture. Schools sit at the heart of this, and at their best they bring adults and children together in ways that foster resonance with one another. They are vital to building solidarity.
For the past several decades, technology has chipped away at the cultural foundations of our educational practices. Years ago, tech enthusiasts argued that we should “personalize learning” using algorithms to provide students with customized and unique educational experiences—although the first wave of efforts largely failed, the dream is being rapidly revived using generative AI. Along the same lines, there is ample evidence that high school and college students are using chatbots to write their essays for them—and efforts are underway to use AI to grade essays too. Perhaps we will soon have a closed loop of machines talking to machines, with nary a human thought in the middle.
That’s a bit extreme, of course, but there’s a very real risk here. We write to discover our thoughts and express them to other humans. We go to school to be with our friends, and to learn from our teachers. Fundamentally, education is one of the methods—perhaps the primary method—though which we build human solidarity. Generative AI is capable of producing words, but in the words and illustrations of artist Angie Wang, it has no life of its own to describe.

We should be wary of employing this technology in the institutions that affirm the essential if ineffable nature of being human.
Conclusion
This essay began with two questions—are we on the cusp of creating artificial general intelligence, and what might this portend for education? By examining how humans think, and contrasting this with how generative AI based on large-language models work, my hope is that you now feel more capable of answering these questions yourself. The Terminator movies bear an outsized and perhaps unhelpful imprint upon our collective fears about the future of artificial intelligence, but there’s a prescient quote in the second film that’s worth bearing in mind:
"The future is not set. There is no fate but what we make for ourselves."
The future of AI is within our collective control, and the choices we make will decide our collective fate. We can use cognitive science to help inform our understanding of this new tool, and to make better decisions about whether and how to make use of it.

[2] https://openai.com/index/planning-for-agi-and-beyond/
[3] https://www.livemint.com/technology/tech-news/elon-musk-says-ai-will-be-smarter-than-any-single-human-by-next-year-how-close-are-we-to-agi-openai-meta-google-11710299436779.html
[4] Miller, George (March 2003). "The cognitive revolution: a historical perspective". Trends in Cognitive Sciences. 7 (3): 141–144. doi:10.1016/S1364-6613(03)00029-9.
[5] Willingham, D.T., & Riener, C. (2019). Cognition: The Thinking Animal, 4. Cambridge, UK: Cambridge University Press.
[6] Willingham, D.T. (2009). Why Don't Students Like School?, 2. Hoboken, NJ: Jossey-Bass.
[7] This model is adapted from Willingham, note 6.
[8] Kidd C, Hayden BY. The Psychology and Neuroscience of Curiosity. Neuron. 2015 Nov 4;88(3):449-60. doi: 10.1016/j.neuron.2015.09.010.
[9] Willingham, D. T. (2017). The Reading Mind: A Cognitive Approach to Understanding How the Mind Reads. Jossey-Bass.
[10] Fernández G, Morris RGM. Memory, Novelty and Prior Knowledge. Trends Neurosci. 2018 Oct;41(10):654-659. doi: 10.1016/j.tins.2018.08.006.
[11] Baddeley, A. (2018). Exploring Working Memory: Selected Works of Alan Baddeley. Oxford, UK: Routledge.
[12] Tooby J., Cosmides L. 2005. Conceptual foundations of evolutionary psychology. In Handbook of evolutionary psychology (ed. Buss D. M.), pp. 5–67 Hoboken, NJ: Wiley.
[13] Heyes, C. (2018). Cognitive Gadgets: The Cultural Evolution of Thinking. Harvard University Press.
[14] Heyes C. New thinking: the evolution of human cognition. Philos Trans R Soc Lond B Biol Sci. 2012 Aug 5;367(1599):2091-6. doi: 10.1098/rstb.2012.0111.
[15] Dawkins, R. (1989). The Selfish Gene. Oxford, UK: Oxford University Press.
[16] https://the-decoder.com/gpt-4-architecture-datasets-costs-and-more-leaked/#:~:text=Dataset%3A%20GPT%2D4%20is%20trained,data%20from%20ScaleAI%20and%20internally.
[17] Marcus, G. (2001). The Algebraic Mind: Integrating Connectionism and Cognitive Science. MIT Press.
[18] Technically, large-language models actually treat text as “tokens,” meaning they break words down into smaller components and use this these tokens as their vocabulary – but we’ll just use words to make things simpler. For more on tokenization in LLMs: https://seantrott.substack.com/p/tokenization-in-large-language-models

[20] https://cacm.acm.org/blogs/blog-cacm/276268-can-llms-really-reason-and-plan/fulltext
[21] This specific task was created by Colin Fraser, an engineer at Meta.
[22] https://arxiv.org/pdf/2311.09247
[23] https://arxiv.org/pdf/2309.13638
[24] https://arxiv.org/pdf/2309.12288
[25] https://openai.com/blog/planning-for-agi-and-beyond
[27] https://sites.rutgers.edu/critical-ai/wp-content/uploads/sites/586/2022/01/Bender_AI-and-Everything-in-the-Whole-Wide-World-Benchmark.pdf
[28] Raji, id.
[29] https://twitter.com/fchollet/status/1722313801503220133
[30] https://www.deansforimpact.org/tools-and-resources/the-science-of-learning
[31] https://www.ailiteracyday.org/
[32] https://script-ed.org/article/algorithmic-colonization-of-africa/
[33] https://pitchbook.com/news/articles/generative-ai-seed-funding-drops
[34] https://dl.acm.org/doi/10.1145/3442188.3445922
[36] Rorty, R. (1989) Contingency, Irony, and Solidarity. Cambridge University Press, Cambridge. http://dx.doi.org/10.1017/CBO9780511804397.
Nice overview of AGI in relation to the question of the educational value of generative AI models. I especially like your pointing to what I think of as the "Grover paper" as it calls attention to the limits of the datasets the models are trained on relative to human experience. While the more famous "Stochastic Parrot" paper focuses on the significant differences in how LLMs and humans generate words, the difference in inputs are perhaps more important in explaining why LLMs are not "thinking" in any way similar to the way humans do.
Do you think tutoring can happen through text processing without reasoning?