

Agentic AI gets lost
On the failure of AI to develop world models

It’s an awkward time on the human-cognition-versus-AI beat, let me tell you, because:
1. The vast majority of normal human beings who use generative AI, I’d guesstimate somewhere between 95 to 99 percent, are presently doing so via written interactions with “classic” large-language models such as ChatGPT. Write a prompt, get a reply, lather rinse repeat.
2. Despite the versatility of these interactions being the very thing that’s led to mass AI hysteria broad exuberance about AI capabilities, we are now explicitly being told by the Big Tech companies that chatbots are not, repeat not, the future of AI. Prompt engineering is dead, long live Agentic AI.
3. As best I can tell, Agentic AI presently has three broad use cases, all of which give me a headache:
a. Coding. If you need to engineer some new software, you can tell Agentic AI what you want in general terms and it may provide you with something potentially useful. This, I concede, may prove to be an economically significant development, given how broadly software permeates every aspect of our society. But I myself have little need for custom-written code, nor am I interested in becoming an amateur computer programmer. I have nowhere really to go with this.
b. Convincing large businesses that they can save money. AI is really good at is ingesting vast amounts of data. As such, if you are a large corporation that possesses vast amounts of data, your leadership might be convinced that unleashing Agentic AI will discover new cost efficiencies, perhaps by rendering the need for middle managers obsolete. It’s not clear to me that this perceived use-case is in fact true, but for me personally it doesn’t matter, because I am not sitting on a trove of data to mine for cost savings. AI as Office Space is fundamentally uninteresting to me.
c. “Vacation planning.” Another use of Agentic AI is to grant it access to our personal computers and smartphones and allowing it to manage our digital affairs—vacation planning is the go-to example. (Check out this research on “Agentic AI for Trip Planning Optimization Application.”) The thing is, I enjoy planning my own vacations, it’s not a process I find the need to “optimize.” And the even bigger problem is that there’s no part of me that trusts these Agentic AI tools to invade my digital space. So, there’s little testing of them that I can do on this front.
You see my dilemma. For all my many criticisms of generative AI chatbots, at least these things provide an interesting non-example of human cognition to mess around with. But how the hell am I supposed to probe the cognitive capacities of Agentic AI?
Time for some Zork!
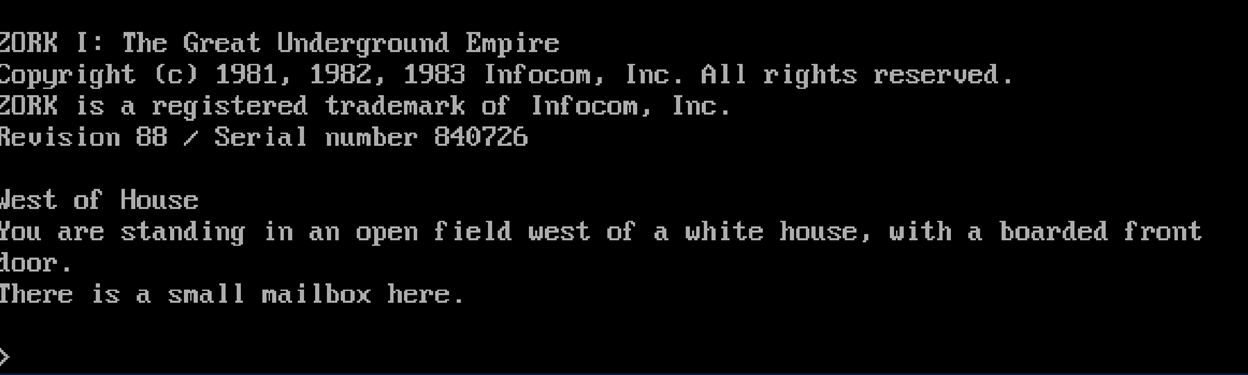
If you recognize this screen, congratulations, you’re old and nerdy. For the less familiar, Zork is a classic computer game created at MIT in the late 1970s and released commercially in the early 1980s by Infocom, the company that pioneered text-based interactive games. You see kids, back then our newfangled “microcomputers” couldn’t really process things called “graphics.” So instead we got text-based choose-your-own-adventure style games wherein we, the human players, would type various prompts that (we hoped) would lead to meaningful discoveries to drive the game narrative forward.
For Zork itself, this meant exploring a subterranean world known as the “Great Underground Empire” and collecting various treasures while avoiding being eaten by Grues or having your shit stolen by the infuriating Thief.1 It was fun and maddening. On the fun side, I spent many hours with Justin M., my best friend in childhood, drawing maps of the strange abstract world we were exploring.2 (As I discovered in the course of writing this essay, there’s an entire cottage industry of Zork maps, including the one I pasted above.)
The maddening part often involved figuring out how to phrase something such that the software would respond in meaningful fashion, rather than saying “I don’t know [word you just typed]” repeatedly and eventually taunting you for your stupidity:

Ok, so. Just a few months ago, Berry Gerrits, a researcher in the Netherlands, had the fun idea to test the current state-of-the-art LLMs—versions of Claude, ChatGPT, and Gemini—on their ability to play Zork.3 As he observes, Zork is a great game for comparing and constrasting human thinking with how LLMs do what they do:
What makes Zork particularly relevant for testing LLMs is how it depends on distinctly human cognitive capacities. Human players leverage imagination to construct mental representations from textual descriptions, apply commonsense world knowledge to reason about object properties and causal relationships (understanding, for instance, that a lantern provides light, or that a sword can kill someone), and should continuously reflect on their own strategies, i.e., show some level of metacognition…[T]hese games reveal the sophisticated interplay between language comprehension, spatial reasoning, planning, and problem-solving that characterizes human intelligence.
The question we address in this paper is whether contemporary LLMs can exhibit the flexible, goal-oriented problem-solving that text adventure games like Zork demands, or whether their performance reveals a lack of genuine understanding that [Melanie] Mitchell identifies as characteristic of systems that have learned shortcuts rather than true conceptual understanding.
This is what cognitive scientists call a “world model,” meaning, a set of mental representations that we humans form about (ahem) the world and how we expect it to function. A very big question hovering over AI is whether it’s possible for such systems to develop world models akin to what humans possess. (This is why AI gurus such as Yann LeCun, who readers may remember from my “exclusive interview” last year, is currently devoting his attention and efforts to this task, which he amusingly calls LeWorldModel. Fei-Fei Li, another OG of AI research, likewise has launched an AI effort called World Labs.)
As best I can tell, Gerrits tested LLMs in their “classic” chatbot-based format, activating “reasoning” mode on occasion, but making no use of their agentic capacities.4 And in this classic mode, their performance was unimpressive, as the models uniformly struggled to advance beyond the initial phases of the game: out of 350 possible points, none exceeded 75 (21%), and most of the time they scored much lower than that. Most damningly, the chatbots did not evidence the capacity for in-context learning. Instead, “they often continued attempting unsuccessful actions without adapting their approach, and failed to learn from mistakes across multiple game sessions. These patterns point to a fundamental distinction between pattern matching and genuine understanding.”
So classic LLMs suck at Zork—but what about Agentic AI? We’ve been told it’s both incredibly powerful and adept at solving problems with only minimal guidance. Might Agentic AI therefore be more capable at navigating the Great Underground Empire and gathering the treasures of Zork?
To answer that question, I forked over $20 to renew my access to ChatGPT Pro, which includes an “agent mode” that can be activated up to 50 times per month. I then ran 10 open-ended trials wherein I pointed the AI to the online Zork emulator and told it to “play to win.” And…and…
Reader, it did not win. In fact, Agentic Chat did very poorly. The chart below summarizes the results, but in brief, the highest score it achieved was 40 out of 350, about the same as the classic LLMs that Gerrits tested.
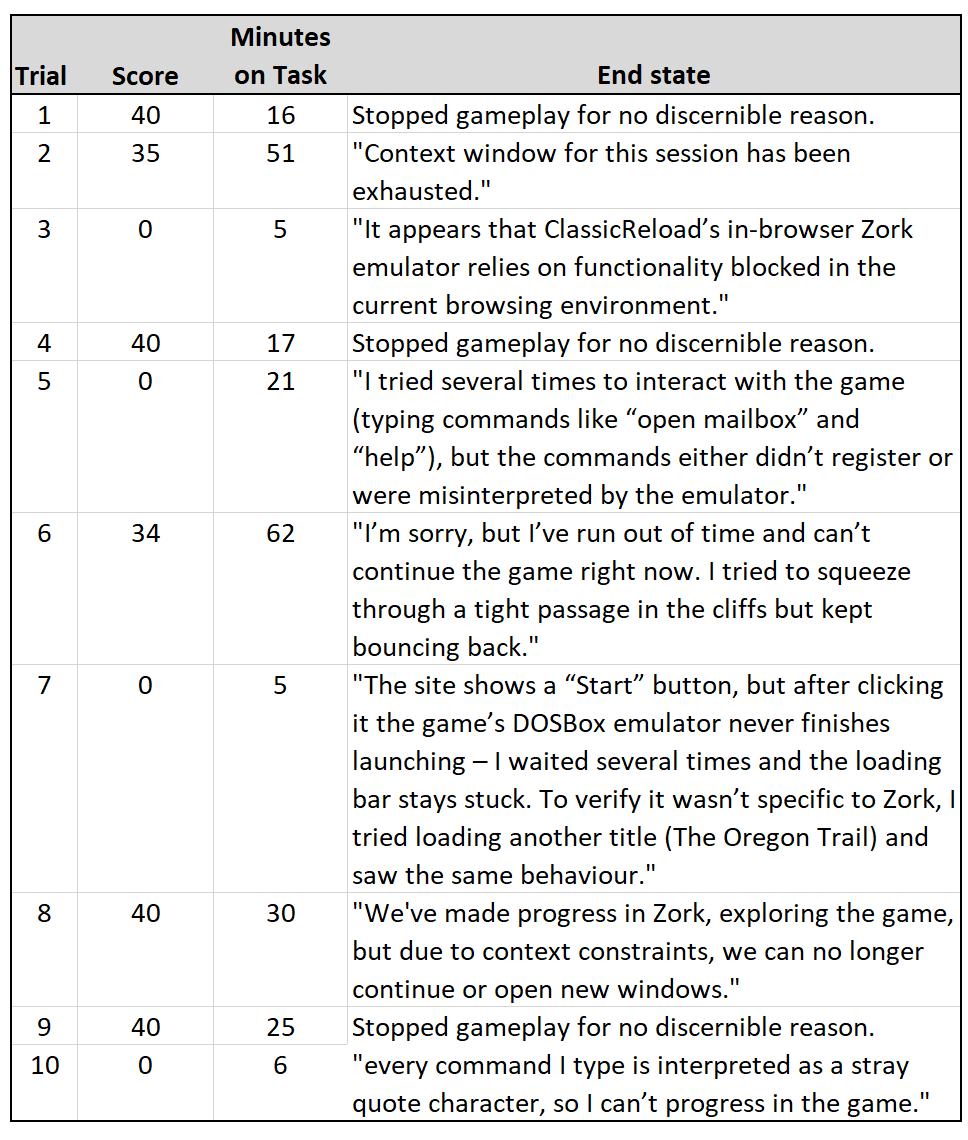
This is just a small test of course, hardly definitive proof of anything. But at least in these trials, I found no evidence of Chat’s agentic mode developing anything remotely akin to a Zorkian world model. It would make valid moves but with no discernible end goal in mind. Basically, there was a lot of this:
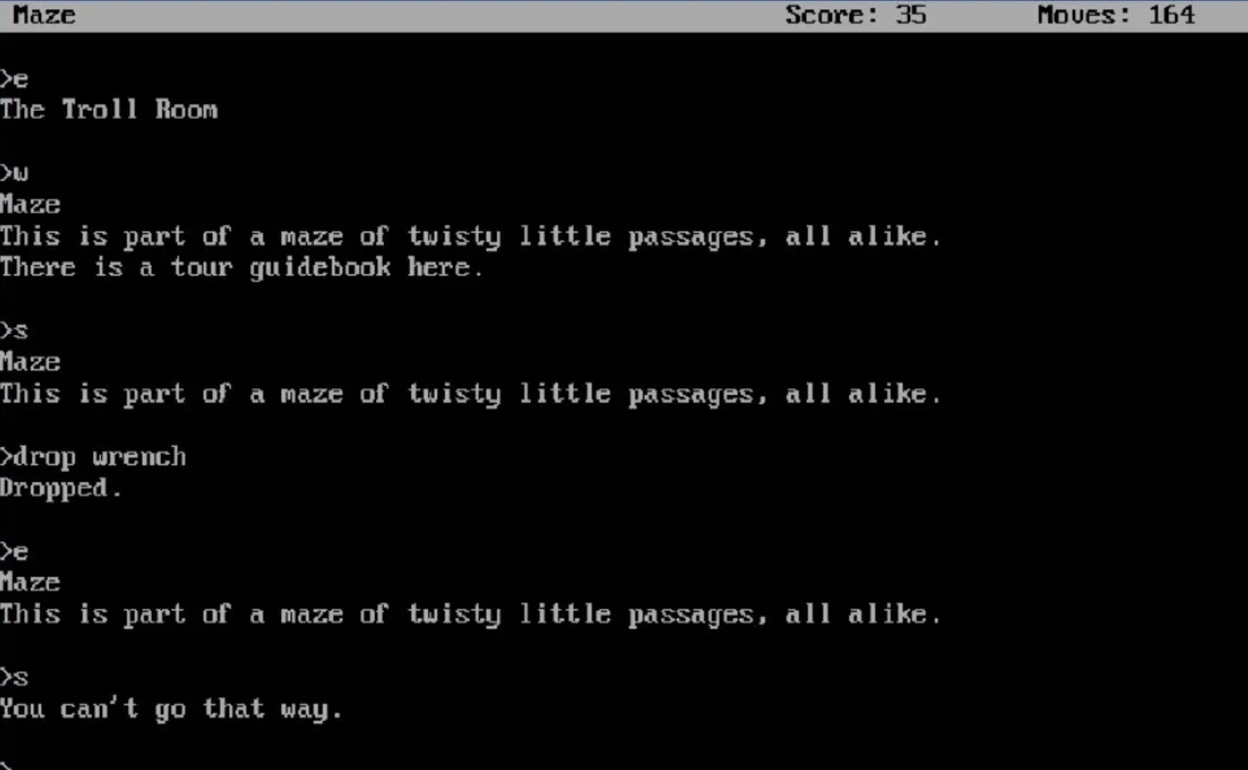
This is Agentic AI as clumsy lobotomized hamster.
More charitably, it’s impressive that Agentic Chat managed to play this Zork emulator despite ongoing interference from random pop-up ads (I chuckled when “Am I gay? Take this test!” spam started causing problems). Further, I am very curious how Anthropic’s agentic models would fare playing Zork, given that Agentic Claude is considered best in class at the moment. But I’m resistant to giving any money to Anthropic, in part because I think their CEO is an ass, in part because because I’m terrified that their per-token pricing might bankrupt me. That said, if anyone out there has a subscription and wants to investigate this together, please get in touch.
Here’s my hunch: over time, Agentic AI tools will get better at games such as Zork, just as they’ve improved on other complex, deterministic tasks. But will this improvement result from using efficient world modeling, the way that humans do? Or will they continue to use relatively brute force computing techniques that are as costly as they are inelegant?
Somewhere, Melanie Mitchell is nodding, because—from a scientific perspective—it’s not just whether AI can solve certain problems, but also how. As such, if we really are entering the “era of agentic AI” (whatever that means), it seems we still will have interesting possibilities for comparing and contrasting how we humans think to how these tools do what they do. Or so I am choosing to believe, perhaps out of professional necessity.
Next week: Can Agentic AI avoid dying of dysentery?
According to the player’s guide that accompanied the original game, the Great Underground Empire “collapsed in 883 GUE after centuries of excessive taxation and royal decadence,” which raises some interesting socio-political questions about the Zork economy that unfortunately are beyond our scope here.
I’m still friends with Justin, and he texted me this about our Zork-playing days: “Infocom games were the best! They were a bit over our heads, but we’d plug away at ‘em regardless. I remember [with Zork] we had to go in specific directions and if you screwed up, you’d end up in the same place – I smashed a few keyboards over that game for sure. But great wit and engaging writing. They challenged you into being cerebral.”
Some light Internet sleuthing suggests Gerrits is also interested in how AI might help cultivate craft beer, so clearly we are destined to be friends. Oh and shout out to René Walter for pointing me to Gerrit’s research in the first place—Walter’s newsletter always makes for interesting reading.
From the Methodology section: “The game is accessed through a browser-based implementation. A custom built Python script connects the LLM and the game environment. The script captures the game’s output after each move, forwards it to the LLM, receives the model’s command, and inputs this command back into the game. The LLM has access to the full conversation of the current run.”
I've been interesting in this domain as a benchmark as well. I implemented my own small custom dungeon, and have been testing it with various harnesses. And yes, currently LLM agents are awful:
https://derekjames.substack.com/p/youre-standing-in-a-clearing-in-a
https://derekjames.substack.com/p/text-adventure-benchmarks-revisited
What's interesting about Zork in particular is that yes, it's a deterministic domain with lots of walkthroughs on the internet. Either that info is getting drowned out, or the LLMs have a very difficult time translating declarative information into actionable steps, or something else. But even if they could solve the original design of Zork, it would be fairly straightforward to randomize elements of the map and puzzles to keep it the solution from being deterministic. We're not even there yet though.
OK this is awesome and I love it.
I want to know how the best AI would do at nethack also! Who's got the money and spare time to throw at it?